
MySQL索引定義:索引(Index) 是幫助MySQL高效獲取數據的數據結構。 提取句子主干, 就可以得到索引的本質: 索引是數據結構。
大部分數據庫系統及文件系統都采用B-Tree或其變種B+Tree作為索引結構
數據結構具體應用場景:
數據庫是如何做到快速檢索的功能。
特別有意思的小例子。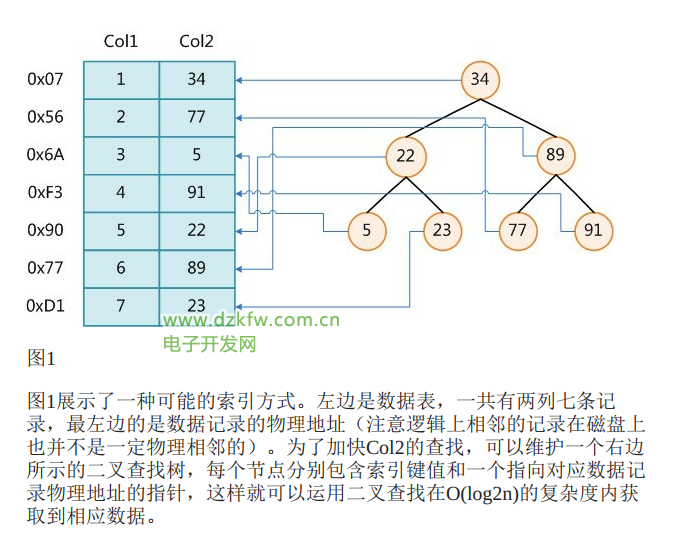
mysql索引原理的理解和數據結構
數據結構
B+樹(為什么使用B+數)
- 所有數據都存儲在磁盤中,讀取數據由于IO問題會讀取慢,如何加快IO速度
IO
- 量:減少IO量
*禁止使用slect ,避免增加不必要的量 - 次數:減少IO次數
相關知識點
- 加入索引(加快查詢速度)
- 數據結構設計:key、文件編號、當前文件的offset(存在問題:當數據量特別大時,索引所占用的存儲空間也特別大。)
- 解決方法:索引的數據文件也需要持久化存儲到磁盤中,當需要使用時直接讀取到內存中,加快數據的訪問(分而治之:分塊讀取)
- 操作系統基本概念:
1.局部性原理:數據和程序都有聚集成群的傾向,之前被查詢過的數據很快會再次被查詢。冷熱數據(一級緩存,二級緩存的意思)
2.磁盤預讀:在數據交換時,會有一個基本邏輯單位頁,一般占用空間是4k,每次在進行數據獲取時可以獲取整頁的整數倍。(mysql中innodb的存儲引擎讀取數據會讀取16k show variables like ‘%innodb’)
ket-value格式數據結構存儲:
- 哈希表
- 樹(二叉樹、BST、AVL、紅黑樹、B樹、B+樹)
二分支的缺點:深度太深,解決方法:B樹(多叉樹)
B樹
- 搜索樹
- 多節點多分支的數
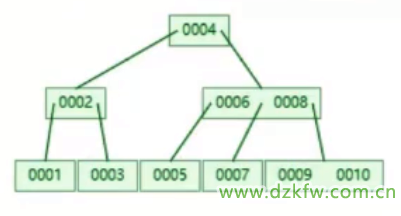
問題:假設磁盤塊存放16條數據,如果是三層樹,最多存放的數據:161616=4096,即48k才存放4096條數據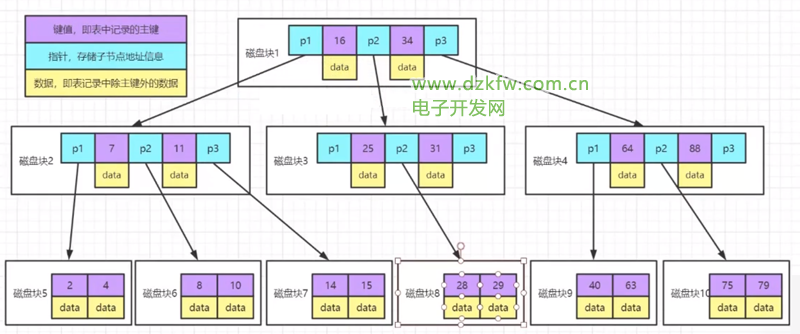
B數存在問題:存放了數據,依然占用空間,如何減少數據,需要用到B+數
B+樹
- 最下面的葉子節點存放的是順序全量數據
- 非葉子節點可以不用存放data
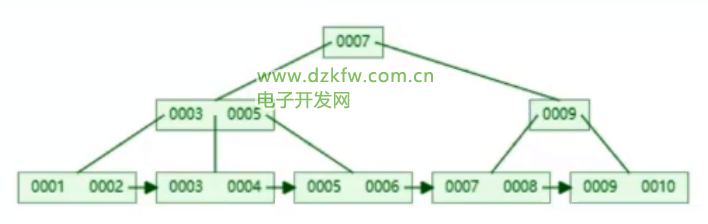
- 問題:讀取數據,假設三層樹48k磁盤塊,1000字節為1kb,指針和鍵值占10字節,1行記錄1k 161000/10=160016001600=40960000的數據范圍,即Key鍵值,最下面的只存放一遍數據*
- 建索引時,key要盡可能少的占用空間

索引技術名詞
**回表:**從非聚簇索引跳轉到聚簇索引中查找數據的過程(避免回表操作select * from table )
索引覆蓋當非聚簇索引的葉子節點中包含了查詢需要的所有字段時,不需要回表的過程(推薦使用select id,name from table )
最左匹配:、索引下推
 返回頂部
返回頂部 刷新頁面
刷新頁面 下到頁底
下到頁底