
數(shù)據(jù)結(jié)構(gòu)和算法是相輔相成的。數(shù)據(jù)結(jié)構(gòu)是為算法服務(wù)的,算法要作用在特定的數(shù)據(jù)結(jié)構(gòu)之上。 因此,我們無法孤立數(shù)據(jù)結(jié)構(gòu)來講算法,也無法孤立算法來講數(shù)據(jù)結(jié)構(gòu)。
比如,因為數(shù)組具有隨機(jī)訪問的特點,常用的二分查找算法需要用數(shù)組來存儲數(shù)據(jù)。但如果我們選擇鏈表這種數(shù)據(jù)結(jié)構(gòu),二分查找算法就無法工作了,因為鏈表并不支持隨機(jī)訪問。
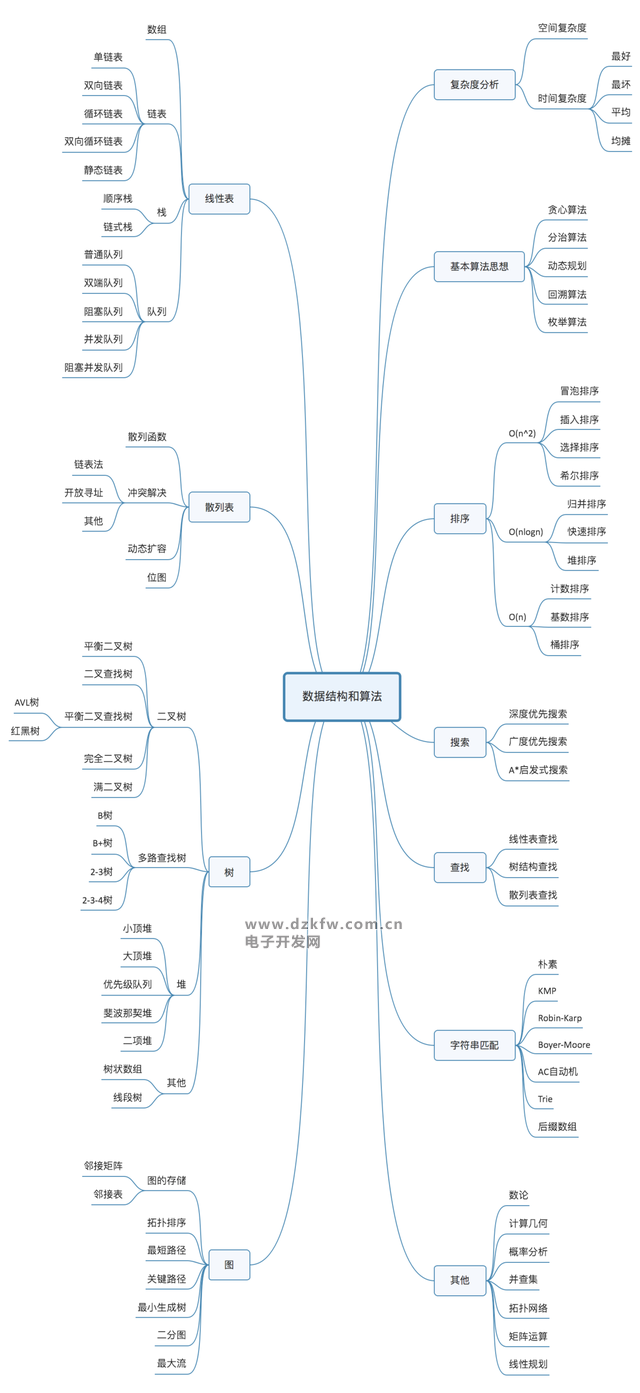
10 個數(shù)據(jù)結(jié)構(gòu):數(shù)組、鏈表、棧、隊列、散列表、二叉樹、堆、跳表、圖、Trie 樹;
10 個算法:遞歸、排序、二分查找、搜索、哈希算法、貪心算法、分治算法、回溯算法、動態(tài)規(guī)劃、字符串匹配算法。
要學(xué)習(xí)它的“來歷”“自身的特點”“適合解決的問題”以及“實際的應(yīng)用場景”。
千萬不要被動地記憶,要多辯證地思考,多問為什么。
一些可以讓你事半功倍的學(xué)習(xí)技巧:
-
邊學(xué)邊練,適度刷題
-
多問、多思考、多互動
-
-
知識需要沉淀,不要想試圖一下子掌握所有
學(xué)習(xí)的過程中,我們碰到最大的問題就是,堅持不下來。
我們在枯燥的學(xué)習(xí)過程中,也可以給自己設(shè)立一個切實可行的目標(biāo),就像打怪升級一樣。
1、數(shù)組
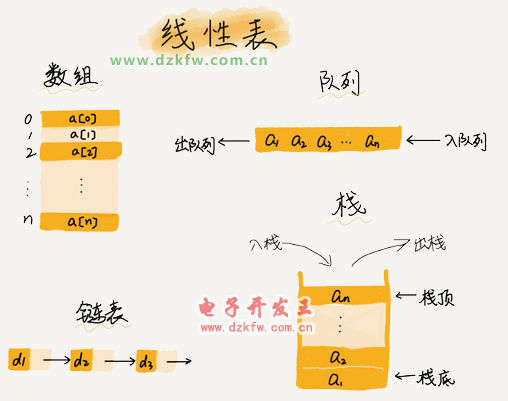
2、鏈表
緩存的大小有限,當(dāng)緩存被用滿時,哪些數(shù)據(jù)應(yīng)該被清理出去,哪些數(shù)據(jù)應(yīng)該被保留?這就需要緩存淘汰策略來決定。常見的策略有三種:先進(jìn)先出策略 FIFO(First In,F(xiàn)irst Out)、最少使用策略 LFU(Least Frequently Used)、最近最少使用策略 LRU(Least Recently Used)。
三種最常見的鏈表結(jié)構(gòu),它們分別是:單鏈表、雙向鏈表和循環(huán)鏈表。
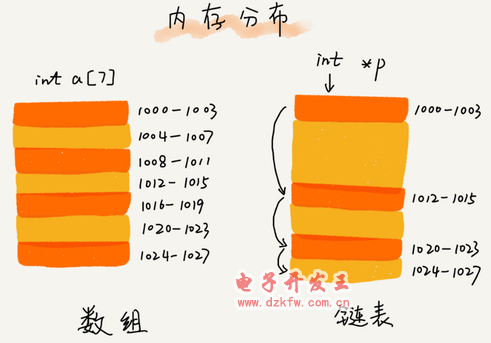
(1)單鏈表
鏈表通過指針將一組零散的內(nèi)存塊串聯(lián)在一起。其中,我們把內(nèi)存塊稱為鏈表的“結(jié)點”。為了將所有的節(jié)點串起來,每個鏈表的結(jié)點除了存儲數(shù)據(jù)之外,還需要記錄鏈上的下一個節(jié)點的地址。如圖所示,我們把這個記錄下個結(jié)點地址的指針叫作后繼指針 next。
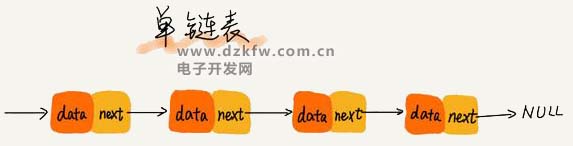
從我畫的單鏈表圖中,你應(yīng)該可以發(fā)現(xiàn),其中有兩個結(jié)點是比較特殊的,它們分別是第一個結(jié)點和最后一個結(jié)點。我們習(xí)慣性地把第一個結(jié)點叫作頭結(jié)點,把最后一個結(jié)點叫作尾結(jié)點。其中,頭結(jié)點用來記錄鏈表的基地址。有了它,我們就可以遍歷得到整條鏈表。而尾結(jié)點特殊的地方是:指針不是指向下一個節(jié)點,而是指向一個空地址 NULL,表示這是鏈表上最后一個節(jié)點。
(2)循環(huán)鏈表

當(dāng)要處理的數(shù)據(jù)具有環(huán)型結(jié)構(gòu)特點時,就特別適合采用循環(huán)鏈表。比如著名的約瑟夫問題。
(3)雙向鏈表
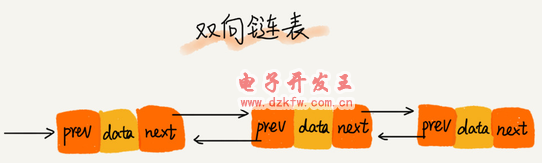
雙向鏈表需要額外的兩個空間來存儲后繼結(jié)點和前驅(qū)結(jié)點的地址。所以,如果存儲同樣多的數(shù)據(jù),雙向鏈表要比單鏈表占用更多的內(nèi)存空間。雖然兩個指針比較浪費存儲空間,但可以支持雙向遍歷,這樣也帶來了雙向鏈表操作的靈活性。
雙向鏈表可以支持 O(1) 時間復(fù)雜度的情況下找到前驅(qū)結(jié)點。

所以數(shù)組適合做查詢,比如查詢算法都是用數(shù)組,鏈表適合做儲存,比如lru會考慮鏈表。
如何輕松寫出正確的鏈表代碼?
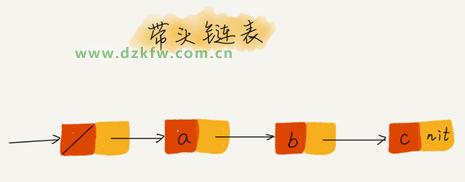
還記得如何表示一個空鏈表嗎?head=null 表示鏈表中沒有結(jié)點了。其中 head 表示頭結(jié)點指針,指向鏈表中的第一個節(jié)點。
如果我們引入哨兵結(jié)點,在任何時候,不管鏈表是不是空,head 指針都會一直指向這個哨兵結(jié)點。我們也把這種有哨兵結(jié)點的鏈表叫帶頭鏈表。相反,沒有哨兵結(jié)點的鏈表就叫作不帶頭鏈表。
哨兵結(jié)點是不存儲數(shù)據(jù)的。因為哨兵結(jié)點一直存在,所以插入第一個結(jié)點和插入其他結(jié)點,刪除最后一個節(jié)點和刪除其他結(jié)點,都可以統(tǒng)一為相同的代碼實現(xiàn)邏輯了。
3、棧
當(dāng)某個數(shù)據(jù)集合只涉及在一端插入和刪除數(shù)據(jù),并且滿足后進(jìn)先出、先進(jìn)后出的特性,我們就應(yīng)該首選“棧”這種數(shù)據(jù)結(jié)構(gòu)。
比較經(jīng)典的一個應(yīng)用場景就是1、 函數(shù)調(diào)用棧.2、棧在表達(dá)式求值中的應(yīng)用3、棧在括號匹配中的應(yīng)用
leetcode上關(guān)于棧的題目大家可以先做20,155,232,844,224,682,496.
4、隊列
循環(huán)隊列
循環(huán)隊列,顧名思義,它長得像一個環(huán)。原本數(shù)組是有頭有尾的,是一條直線。現(xiàn)在我們把首尾相連,扳成了一個環(huán)。
阻塞隊列
阻塞隊列其實就是在隊列基礎(chǔ)上增加了阻塞操作。簡單來說,就是在隊列為空的時候,從隊頭取數(shù)據(jù)會被阻塞。因為此時還沒有數(shù)據(jù)可取,直到隊列中有了數(shù)據(jù)才能返回;如果隊列已經(jīng)滿了,那么插入數(shù)據(jù)的操作就會被阻塞,直到隊列中有空閑位置后再插入數(shù)據(jù),然后再返回。
并發(fā)隊列
線程安全的隊列我們叫作并發(fā)隊列。最簡單直接的實現(xiàn)方式是直接在 enqueue()、dequeue() 方法上加鎖,但是鎖粒度大并發(fā)度會比較低,同一時刻僅允許一個存或者取操作。
5、跳表
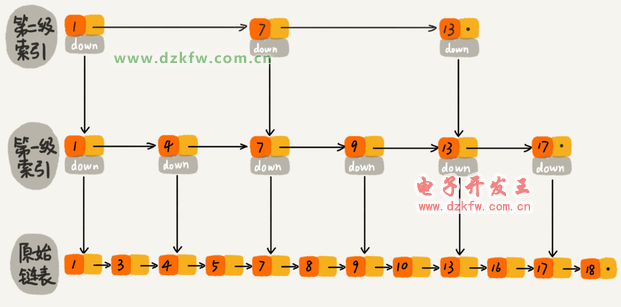
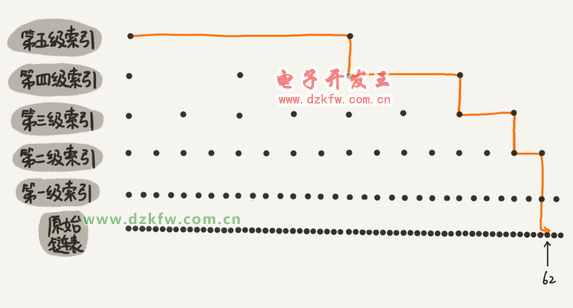
這種鏈表加多級索引的結(jié)構(gòu),就是跳表。
用跳表查詢到底有多快?
第 k 級索引的結(jié)點個數(shù)是第 k-1 級索引的結(jié)點個數(shù)的 1/2,那第 k級索引結(jié)點的個數(shù)就是 n/(2k)。
時間復(fù)雜度: O(m*logn)。
跳表是不是很浪費內(nèi)存?
跳表需要存儲多級索引,肯定要消耗更多的存儲空間。
跳表的空間復(fù)雜度是 O(n)。
為什么 Redis 要用跳表來實現(xiàn)有序集合,而不是紅黑樹?
Redis 中的有序集合支持的核心操作主要有下面這幾個:
-
插入一個數(shù)據(jù);
-
刪除一個數(shù)據(jù);
-
查找一個數(shù)據(jù);
-
按照區(qū)間查找數(shù)據(jù)(比如查找值在 [100, 356] 之間的數(shù)據(jù));
-
迭代輸出有序序列。
其中,插入、刪除、查找以及迭代輸出有序序列這幾個操作,紅黑樹也可以完成,時間復(fù)雜度跟跳表是一樣的。但是,按照區(qū)間來查找數(shù)據(jù)這個操作,紅黑樹的效率沒有跳表高。
對于按照區(qū)間查找數(shù)據(jù)這個操作,跳表可以做到 O(logn) 的時間復(fù)雜度定位區(qū)間的起點,然后在原始鏈表中順序往后遍歷就可以了。這樣做非常高效。
還有,跳表更加靈活,它可以通過改變索引構(gòu)建策略,有效平衡執(zhí)行效率和內(nèi)存消耗。
6、二叉樹
7、Trie樹(字典樹)
Trie 樹,也叫“字典樹”。顧名思義,它是一個樹形結(jié)構(gòu)。它是一種專門處理字符串匹配的數(shù)據(jù)結(jié)構(gòu),用來解決在一組字符串集合中快速查找某個字符串的問題。
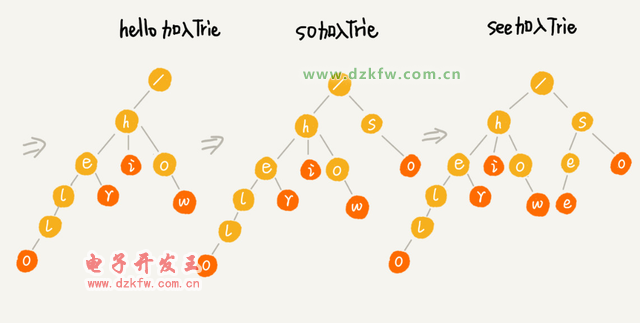
Trie 樹主要有兩個操作
-
一個是將字符串集合構(gòu)造成 Trie 樹,就是一個將字符串插入到 Trie 樹的過程。
-
另一個是在 Trie 樹中查詢一個字符串。
Trie 樹的變體有很多,都可以在一定程度上解決內(nèi)存消耗的問題。比如,縮點優(yōu)化
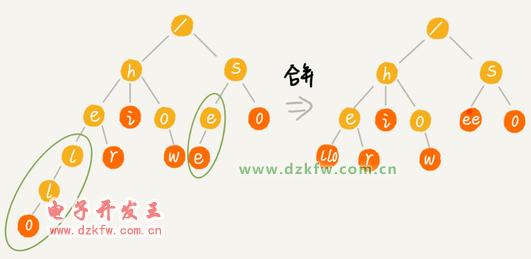
在一組字符串中查找字符串,Trie 樹實際上表現(xiàn)得并不好。它對要處理的字符串有及其嚴(yán)苛的要求。
-
第一,字符串中包含的字符集不能太大。我們前面講到,如果字符集太大,那存儲空間可能就會浪費很多。即便可以優(yōu)化,但也要付出犧牲查詢、插入效率的代價。
-
第二,要求字符串的前綴重合比較多,不然空間消耗會變大很多。
-
第三,如果要用 Trie 樹解決問題,那我們就要自己從零開始實現(xiàn)一個 Trie 樹,還要保證沒有 bug,這個在工程上是將簡單問題復(fù)雜化,除非必須,一般不建議這樣做。
-
第四,我們知道,通過指針串起來的數(shù)據(jù)塊是不連續(xù)的,而 Trie 樹中用到了指針,所以,對緩存并不友好,性能上會打個折扣。
綜合這幾點,針對在一組字符串中查找字符串的問題,我們在工程中,更傾向于用散列表或者紅黑樹。因為這兩種數(shù)據(jù)結(jié)構(gòu),我們都不需要自己去實現(xiàn),直接利用編程語言中提供的現(xiàn)成類庫就行了。
實際上,Trie 樹只是不適合精確匹配查找,這種問題更適合用散列表或者紅黑樹來解決。Trie 樹比較適合的是查找前綴匹配的字符串,也就是類似開篇問題的那種場景。
8、散列表(Hash Table)
散列表(哈希表)用的是數(shù)組支持按照下標(biāo)隨機(jī)訪問數(shù)據(jù)的特性,所以散列表其實就是數(shù)組的一種擴(kuò)展,由數(shù)組演化而來。可以說,如果沒有數(shù)組,就沒有散列表。
一般有key和value,key會通過散列函數(shù)轉(zhuǎn)換成散列值
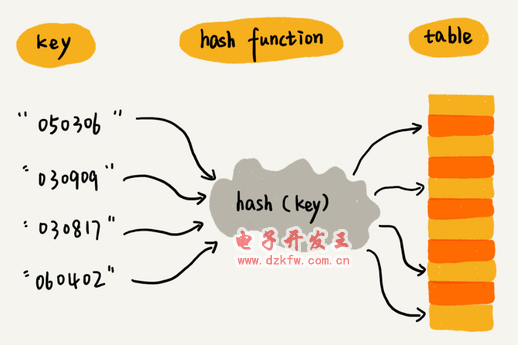
散列函數(shù)(哈希函數(shù))
散列表兩個核心問題是散列函數(shù)設(shè)計和散列沖突解決。
散列函數(shù)設(shè)計的基本要求:
-
散列函數(shù)計算得到的散列值是一個非負(fù)整數(shù);
-
如果 key1 = key2,那 hash(key1) == hash(key2);
-
如果 key1 ≠ key2,那 hash(key1) ≠ hash(key2)。
第一二點沒啥問題,但第三點理解起來可能會有問題,要想找到一個不同的 key 對應(yīng)的散列值都不一樣的散列函數(shù),幾乎是不可能的。即便像業(yè)界著名的MD5、SHA、CRC等哈希算法,也無法完全避免這種散列沖突。而且,因為數(shù)組的存儲空間有限,也會加大散列沖突的概率。
我們常用的散列沖突解決方法有兩類,開放尋址法和鏈表法。
1. 開放尋址法
開放尋址法的核心思想是,如果出現(xiàn)了散列沖突,我們就重新探測一個空閑位置,將其插入。
-
線性探測:如果存儲位置已經(jīng)被占用了,我們就從當(dāng)前位置開始,依次往后查找,看是否有空閑位置,直到找到為止。
-
二次探測:跟線性探測很像,線性探測每次探測的步長是 1,那它探測的下標(biāo)序列就是 hash(key)+0,hash(key)+1,hash(key)+2……而二次探測探測的步長就變成了原來的“二次方”,也就是說,它探測的下標(biāo)序列就是 hash(key)+0,hash(key)+12,hash(key)+22……
-
雙重散列:意思就是不僅要使用一個散列函數(shù)。我們使用一組散列函數(shù) hash1(key),hash2(key),hash3(key)……我們先用第一個散列函數(shù),如果計算得到的存儲位置已經(jīng)被占用,再用第二個散列函數(shù),依次類推,直到找到空閑的存儲位置。
當(dāng)數(shù)據(jù)量比較小、裝載因子小的時候,適合采用開放尋址法。這也是 Java 中的ThreadLocalMap使用開放尋址法解決散列沖突的原因。
2. 鏈表法
所有散列值相同的元素我們都放到相同槽位對應(yīng)的鏈表中。
為什么HashMap使用鏈表法解決哈希沖突
1、首先,鏈表法對內(nèi)存的利用率比開放尋址法要高。因為鏈表結(jié)點可以在需要的時候再創(chuàng)建,并不需要像開放尋址法那樣事先申請好。實際上,這一點也是我們前面講過的鏈表優(yōu)于數(shù)組的地方。
2、鏈表法比起開放尋址法,對大裝載因子的容忍度更高。開放尋址法只能適用裝載因子小于 1 的情況。接近 1 時,就可能會有大量的散列沖突,導(dǎo)致大量的探測、再散列等,性能會下降很多。但是對于鏈表法來說,只要散列函數(shù)的值隨機(jī)均勻,即便裝載因子變成 10,也就是鏈表的長度變長了而已,雖然查找效率有所下降,但是比起順序查找還是快很多。
 返回頂部
返回頂部 刷新頁面
刷新頁面 下到頁底
下到頁底